
PROPOSTA DI PROGETTO
Nome in codice: Odin
Negli anni abbiamo voluto sviluppare una basecode condivisa e replicabile per creare progetti verticali molto in fretta. Il progetto è completamente costruito a moduli con una logica base completamente estendibile a seconda delle esigenze del cliente senza andare ad intaccarne la base.
Odin permette la raccolta e l’elaborazione di dati a campo attraverso algoritmi specifici o IA. I dati possono essere fruiti sia RAW sia aggregati con diverse condizioni che il nostro sistema ti permette di inserire.
< Architettura />
Base estendibile aws
Field Layer (area rossa):
ha il compito di gestire i dati da e verso i device a campo.
Data Layer (area azzurra):
ha il compito di immagazzinare i dati provenienti dal campo e diretti verso il campo.
Presentation Layer (area verde):
ha il compito di esporre delle API in grado di rendere i dati fruibili da GUI esterne e da programmi di terze parti.
I database scelti sono quelli base ma sono cambiabili o estendibili con altre tipologie di database per esempio SQL.
Il cloud scelto è AWS, il progetto è dockerizzato in modo che possa essere compatibile con il maggior numero di provider cloud possibili.
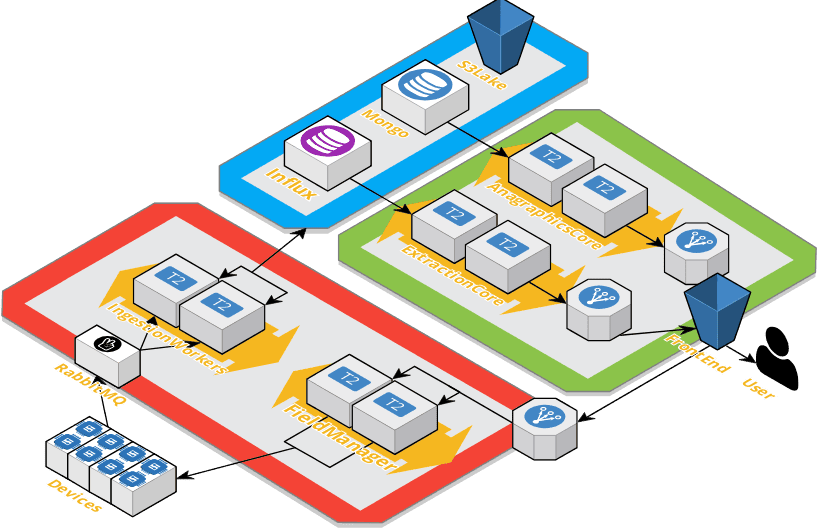
I dati, dopo essere stati generati dai diversi tipi di device a campo vengono immagazzinati in una coda di ingresso e, una volta elaborati dal Field Layer risultato immagazzinabili uniformemente nei database e nelle tabelle corrispondenti. Le regole di standardizzazione dei dati derivano da una combinazione di regole anagrafiche immagazzinate nel database Mongo e da dati passati direttamente dai device. I dati immagazzinati all’interno del Data Layer sono da distinguere in due tipi: dati da campo (generati dai device) e dati di anagrafica (inseriti a mano dall’utente o generati in automatico per autoapprendimento). I dati così salvati vengono poi resi disponibili tramite librerie ORM ad altri servizi (raggruppati nel Presentation Layer) che hanno il compito di renderli fruibili da client REST che forniranno una GUI per l’utente finale. Tramite GUI è anche possibile inviare dei comandi al campo passando sempre per il Field Layer.
Alcuni servizi non inseriti nello schema ma che saranno comunque presenti saranno quelli di Scheduling (necessario per permettere di automatizzare task ricorrenti come watchdog e polling) e quello di SSO. Per il servizio di scheduling verrà utilizzato il modulo node Agenda che permette di schedulare task e di eseguirli in un ambiente distribuito senza gestire manualmente la concorrenza dei processi. Per quanto riguarda le politiche ed i meccanismi di gestione degli accessi e autorizzazione delle richieste da parte dell’SSO verrà utilizzata la tecnologia Bearer, utilizzando un JWT minimale con chiave pubblica/privata.
Per la coda di ingresso i requisiti fondamentali risultati dall’analisi sono stati:
- Monitorabilità dello status della coda
- Gestione di diversi protocolli di comunicazione per l’IoT
- Capacità di una gestione efficace dei dati previsti dal sistema (eventualmente scalando il sistema)
RabbitMQ
Pro | Contro |
|---|---|
Supporto nativo diversi protocolli per IoT | Throughput relativamente basso |
Buona monitorabilità | |
Disponibile in cloud | |
Coda attiva (no polling) |
Kafka
Pro | Contro |
|---|---|
Throughput enorme | Coda passiva (necessità di polling) |
Buona monitorabilità |
La scelta è ricaduta su RabbitMQ a causa del forte supporto nativo (o tramite plugin già esistenti) per diversi protocolli largamente utilizzati nell’IoT (MQTT e HTTP) e per la facilità di implementazione dei worker derivante dalla possibilità di utilizzare pattern di publisher/subscriber per triggerare le elaborazioni.
Per quanto riguarda il database è stato deciso di operare una suddivisione tra il database di Anagrafica ed il database per lo Storico.
Il database scelto per le anagrafiche è stato Mongo che, grazie alla sua flessibilità, permette di realizzare in tempi brevi strutture dati anche complesse, senza vincolare troppo lo sviluppo, permettendo di modificare le scelte prese in fase di analisi senza stravolgimenti dell’applicazione.
Riguardo al database per lo storico la scelta è stata tra relazionale, Cassandra e Influx.
Dopo varie prove di implementazione la scelta è caduta su Influx che si è rivelato estremamente affine nella gestione dei dati, delle serie storiche e delle operazioni legate alle stesse. In seguito per altri verticali abbiamo usufruito di diversi database come SQL o Cassandra ma la nostra prima scelta rimane Influx.
Il codice è prevalentemente scritto in javascript (ES6) e typescript ed eseguito con node, versionato in Git hostato su Atlassian Bitbucket. Alcuni microservizi dedicati all’elaborazione matematica dei dati sono stati invece scritti in Python utilizzando Numpy e Panda. La struttura del versioning è quella raccomandata da Git Flow e il codice è dotato di Continuous Integration e Continuous Delivery realizzata tramite le pipeline di Bitbucket. La tecnologia per unit ed testing è basata su Mocha e Chai.
Per la realizzazione dell’infrastruttura nel cloud si è optato per l’utilizzo di Terraform che ci permette in maniera veloce e pratica di creare ambienti di sviluppo, staging e production multipli.
Tutto il codice Front, back e i middleware sono dotati di continuous integration che permette un versionamento e un deploy automatico del codice.
I progetti sono dockerizzati per garantire la piena indipendenza dall’architettura sottostante
che permette di rendere l’implementazione agnostica rispetto al contesto d’esecuzione.
La documentazione per quanto riguarda le API di intercomunicazione sarà realizzata utilizzando ApiDoc, auto generando i file di documentazione durante la fase di CI e rendendola disponibile sia nel progetto (README.MD) che tramite endpoint sul servizio documentato. Per quanto riguarda la documentazione interna le funzioni principali all’interno del codice sono dotate di commenti JSDoc per una migliore fruizione del codice.
Per ogni progetto viene automaticamente generata una collection di Postman e i suoi environments
Projects:
Gruppo di Impianto/Siti solitamente afferenti ad un singolo cliente.
Plants:
Singolo Impianto/Sito. Solitamente un impianto è un singolo luogo geografico (un’azienda, un capannone, una strada, una stazione) che ha uno o più device.
Device:
Raggruppamento di datapoint. Possono essere reali o virtuali. I datapoint raggruppati nei device possono essere soggetti ad aggregazioni, operazioni matematiche, soglie o allarmi.
Datapoint:
Entità atomica di raccolta delle misurazioni. Un datapoint genererà un singolo tipo di misurazione. Il datapoint è dotato di una misura materializzata che è l’ultima che è stata ricevuta dal sistema (così facendo non ci sarà bisogno di leggere dal database dello storico). I datapoint possono essere reali o virtuali. I dati del singolo datapoint possono essere soggetti ad aggregazioni, operazioni matematiche tra uno o più datapoint, soglie o allarmi e trigger.
Measurement:
Misura atomica generata da un device. Questi dati vengono salvati su un altro database specifico per lo storico (Influx).
AlarmRules:
Condizioni che, data una misura derivante da un datapoint reale o virtuale o da un device , generano una misura di tipo allarme. Gli allarmi sono customizzabili.
Commands e Funzione campo:
Comandi eseguibili su un singolo device o datapoint e istruzioni su come i comandi debbano essere inviati a campo (interni al codice).
Custom*:
Entità che hanno il solo scopo di raggruppare sottoentità di altro tipo in modo da poter avere delle aggregazioni diverse da quelle “rigide” definite dalla struttura a campo.
Device:
Raggruppamento di datapoint. Possono essere reali o virtuali. I datapoint raggruppati nei device possono essere soggetti ad aggregazioni, operazioni matematiche, soglie o allarmi.
Dashboard:
Entità configurabile che permette di posizionare, su una dashboard dinamica per utente, KPI, Soglie, Mappe, sinottici o grafici di misure, device o datapoints.
Report:
Possibilità di esportare i dati in forma raw o aggregata nei formati più comuni.
File, icons Upload:
Possibilità di customizzare device, o entità con set di icone caricabili su S3 e completamente customizzabili dall’utente.